参考文档
编译器
什么是编译器?
从现代高级编译器的角度讲,源语言是高级程序设计语言,容易阅读与编写,而目标语言是机器语言,即二进制代码,能够被计算机直接识别;
从语言系统的处理角度来看,由源程序生成可执行程序。
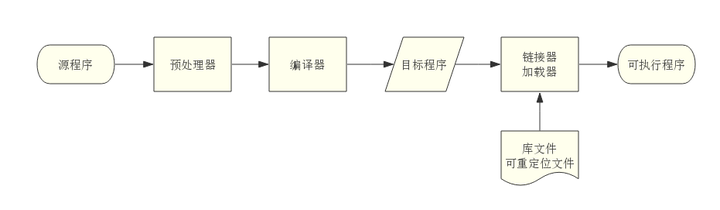
其中,编译器又分为前端和后端两个部分。

Babel
前端人员都知道 Babel,是一个 JS 编译器,它严格按照 ECMA-262 语言规范,实现对最新语法的解析,而无需等待浏览器升级来提供对新特性的支持。Babel 内部所使用的语法解析器是 Babylon,它所使用的 Babylon 实现了编译器中两个部分,词法分析和语法分析。
- Token — 词法单元。在词法中是一个不可分割的最小单元,比如 var,每个 Token 对象都有能够被单独识别的类型属性和其它附加属性(操作符优先级、行列号等)
- 词法分析 — 词法分析是计算机科学中将字符序列转换为单词序列(Token)的过程,从左至右地对源程序进行扫描,按照语言的词法规则识别各类单词,并产生相应单词的属性字。进行词法分析的程序或者函数叫作词法分析器或者扫描器。
- 语法分析 — 语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等, 按照源语言的语法规则,从词法分析的结果中识别出相应的语法范畴,同时进行语法检查。完成语法分析任务的程序称为语法分析器,或语法分析程序
- 文法 — 描述了程序设计语言的构造规则,用于指导整个语法分析的过程。
- AST — 抽象语法树(Abstract Syntax Tree)也称为AST语法树,指的是源代码语法所对应的树状结构
这个 online Parsing 我们可以直观的看到 JS 源码被转换为 Tokens 和 AST 的样子。
Babel 词法分析
在 Babylon 词法分析器里,每个关键字是一个 Token ,每个标识符是一个 Token,每个操作符是一个 Token,每个标点符号也都是一个 Token。除此之外,还会过滤掉源程序中的注释和空白字符(换行符、空格、制表符等)
语法分析
语法分析是词法分析的下一步,主要任务是扫描来自词法分析器产生的 Token 序列,根据文法和结点类型定义构造出一棵 AST,传递给编译器前端余下部分。文法描述了程序设计语言的构造规则,用于指导整个语法分析的过程。
生成代码
最后一个阶段则是生成目标代码,从 AST 的根结点出发,递归下降遍历,对每个结点都调用一个相关函数,执行语义动作,不断打印代码片段,最终生成目标代码,即经过 babel 编译后的代码。

模板引擎
讲到模板引擎,最早诞生于服务端动态页面的开发,如 JSP、PHP、ASP 等模板引擎。Node 之后,又出现了包括 EJS、Handlebars、Pug (前身为 Jade)、Mustache 等等,模板引擎技术使得结合数据渲染视图变得更加灵活。
比较简单的模板引擎,直接利用字符串替换、拼接的方式实现,比较复杂的模板引擎,例如 Pug,则会有比较完整的词法分析和语法分析过程,将模板预编译成 JS 代码再去动态执行。
CSS 预处理器
前端布局方式从刀耕火种的纯 CSS 年代演进到以 Sass、Less、Stylus 为代表的预处理语言,赋予了 CSS 可编程的能力,可以定义变量,函数,表达式计算、模块化等特性
同样,编译器对原样式代码进行词法分析,产生 Token 序列。接着,语法分析,生成中间表示,一棵符合定义的 AST。同时,还会为每个程序块建立一个符号表来记录变量的名字,属性,为代码生成阶段的变量作用域分析提供帮助。最后,递归下降访问 AST,生成能够在浏览器环境中直接执行的 CSS 代码。